
LongEval CLEF 2023 Lab
Longitudinal Evaluation of Model Performance
| Description | Dates | Organizers | Tasks | Data | Submissions |
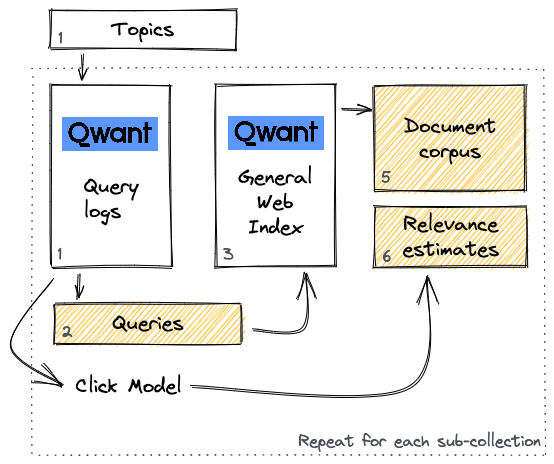
The data for this task is a sequence of web document collections and queries provided by Qwant.
DataQueries:
The queries are extracted from Qwant’s search logs, based on a set of selected topics. The initial set of extracted queries are filtered to exclude spam and queries returning a small number of documents. The query set was created in French and was automatically translated to English.
Documents:
The document collection first includes relevant documents that are selected to be retrieved for each query. The first step for creating the document collection is to extract from the index the content of all the documents that have been displayed in SERPs for the queries that we selected. In addition to these documents, potentially non-relevant documents are randomly sampled from Qwant index in order to better represent the nature of a Web test collection. A random sampling process has been applied to alleviate bias and prevalence of relevant documents. Filters have also been applied to exclude spam and adult content.
Relevance estimates:
The relevance estimates for LongEval-Retrieval are obtained through automatic collection of user implicit feedback. This implicit feedback is obtained with a click model, based on Dynamic Bayesian Networks trained on Qwant data. The output of the click model represents an attractiveness probability, which is turned to a 3-level scale score ( 0 = not relevant, 1 = relevant, 2 = highly relevant). This set of relevance estimates will be completed with explicit relevance assessment after the submission deadline.
The overview of the data creation process is displayed in the Figure below:
The training data and the heldout within a time query set can be downloaded from Lindat/Clarin website. If you experience any problems with loggin to the Lindat/Clarin website, please first check the instructions and contact the organizers. You can find the Readme with the details of the train collection here.
Data in this collection was acquired during June 2022. The document corpus consist of 1,570,734 Web pages. The queries in this Train collection were randomly split into train and heldout queries. The collection consists of 672 train queries, with corresponding 9,656 assessments and 98 heldout queries with corresponding 1,420 assessments. There are thus in average 14 assessments per query. About 73% of the assessments are non-relevant (7,030 assessments on the train queries in total), 21% are relevant (2,028 assessments) and 6% are highly relevant (598 assessments). The table below shows example queries:
| Query ID | French Query | English Query |
|---|---|---|
| q06229550 | bareme impots | Taxation |
| q06223863 | consommation eau | consumption water |
| q06221247 | gateau aux pommes | apple cake |
| q06225303 | offre emploi | offer of employment |
The test collections can be downloaded from the Lindat/Clarin website. The data for the short-term persistence sub-task was collected over July 2022 and this dataset contains 1,593,376 documents and 882 queries. The data for the long-term persistence sub-task was collected over September 2022 and this dataset consists of 1,081,334 documents and 923 queries. The participants are required to submit the results for either one or both test collections and also to submit the results on the heldout Train queries described above. You can find the Readme with the details of the train collection here.
The relevance judgements from the click model can also be downloaded from the Lindat/Clarin website.
Information about the time of indexing and the last time of update for all the documents in the collections can be downloaded here
Practice [Pre-Evaluation]
You can access the COMPETITION HERE and submit to Practice to evaluate your model and practice submittion process
You can download the training and practice sets from here: Training data with two temporal practice sets
CodaLab Submission Format
When submitting to Codalab, please submit a single zip file containing a folder called “submission”. This folder must contain THREE files:
1. predicted_eval_within.txt (with within predictions - interim_eval_2016.json)
2. predicted_eval_short.txt (with distant predictions - interim_eval_2018.json)
3. predicted_eval_long.txt (a BLANK file which will be used for interim_eval_2021.json during the evaluation phase)
Evaluation
You can access the COMPETITION HERE and submit to Evaluation to evaluate your model and rank its performance
You can download the evaluation set from here: Three temporal evaluation sets without gold labels
Evaluation Golden Labeles released: Three temporal evaluation sets with gold labels
CodaLab Submission Format
When submitting to Codalab, please submit a single zip file containing a folder called “submission”. This folder must contain THREE files:
1. predicted_test_within.txt (with within predictions - interim_test_2016.json)
2. predicted_test_short.txt (with distant/short predictions - interim_test_2018.json)
3. predicted_test_long.txt (with distant/long predictions - interim_test_2021.json)
Notes